Due 5pm 2/11/2012 in the TA's emailbox.
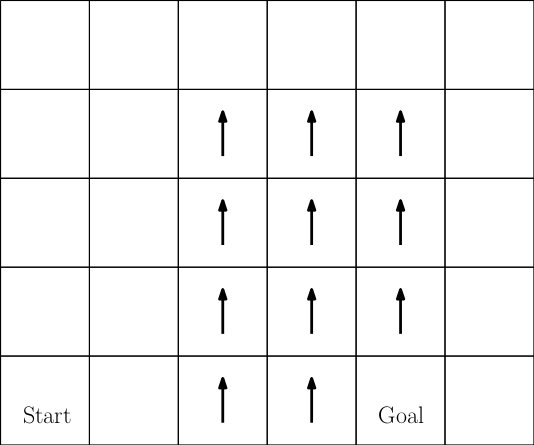
This assignment is to use Reinforcement Learning to solve the following "Windy Grid World" problem illustrated in the above picture. Each cell in the image is a state. There are four actions: move up, down, left, and right. This is a deterministic domain -- each action deterministically moves the agent one cell in the direction indicated. If the agent is on the boundary of the world and executes an action that would move it "off" of the world, it remains on the grid in the same cell from which it executed the action.
Notice that there are arrows drawn in some states in the diagram. These are the "windy" states. In these states, the agent experiences an extra "push" upward. For example, if the agent is in a windy state and executes an action to the left or right, the result of the action is to move left or right (respectively) but also to move one cell upward. As a result, the agent moves diagonally upward to the left or right.
This is an episodic task where each episode lasts no more than 30 time steps. At the beginning of each episode, the agent is placed in the "Start" state. Reward in this domain is zero everywhere except when the agent is in the goal state (labeled "goal" in the diagram). The agent receives a reward of positive ten when it executes any action {\it from} the goal state. The episode ends after 30 time steps or when the agent takes any action after having landed in the goal state.
You should solve the problem using Q-learning. Use e-greedy exploration with epsilon=0.1 (the agent takes a random action 10 percent of the time in order to explore.) Use a learning rate of 0.1 and a discount rate of 0.9.
The programming should be done in MATLAB. Students may get access to MATLAB here. Alternatively, students may code in Python (using Numpy). If the student would rather code in a different language, please see Dr Platt or the TA.
Students should submit their homework via email to the TA (suchismi@buffalo.edu) in the form of a ZIP file that includes the following:
1. A PDF of a plot of gridworld that illustrates the policy and a path found by Q-learning after it has approximately converged. The policy plot should identify the action taken by the policy in each state. The path should begin in the start state and follow the policy to the goal state.
2. A PDF of a plot of reward per episode. It should look like the diagram in Figure 6.13 in SB.
3. A text file showing output from a sample run of your code.
4. A directory containing all source code for your project.
5. A short readme file enumerating the important files in your submission.
You can initialize the Q function randomly or you can initialize it to a uniform value of 10. That is, you can initialize Q such that each value in the table is equal to 10.
There have been questions about how to know when the algorithm has converged. The algorithm has converged when the value function has stopped changing signficantly and the policy has stopped changing completely. Since we are using q-learning, the algorithm should converge to a single optimal policy.
Please also submit a short readme file with your homework that enumerates the important files in your submission.